前言
平时看他人的博客或者看论文的时候,会发现一些很有新意的算法和想法,所以开一篇博客记录一些有趣的算法或者想法。
水塘抽样算法
水塘抽样。水塘抽样是一系列的随机算法,其目的在于从包含n个项目的集合S中选取k个样本,其中n为一很大或未知的数量,尤其适用于不能把所有n个项目都存放到主内存的情况。
一个引例:
首先考虑k为1的情况,即:给定一个长度很大或者长度未知数据流,限定对每个元素只能访问一次,写出一个随机选择算法,使得所有元素被选中的概率相等。
设当前读取的是第n个元素,采用归纳法分析如下:
- n = 1 时,只有一个元素,直接返回即可,概率为1。
- n = 2 时,需要等概率返回前两个元素,显然概率为1/2。可以生成一个0~1之间的随机数p,p < 0.5 时返回第一个,否则返回第二个。
- n = 3 时,要求每个元素返回的概率为1/3。注意此时前两个元素留下来的概率均为1/2。做法是:生成一个0~1之间的随机数,若<1/3,则返回第三个,否则返回上一步留下的那个。元素1和2留下的概率均为:1/2 * (1 - 1/3) = 1/3,即上一步留下的概率乘以这一步留下(即元素3不留下)的概率。
- 假设 n = m 时,前n个元素留下的概率均为:1/n = 1/m;
- 那么 n = m+1 时,生成0~1之间的随机数并判断是否<1/(m+1),若是则留下元素m+1,否则留下上一步留下的元素。这样一来,元素m+1留下的概率为1/(m+1),前m个元素留下来的概率均为:1/m * (1 - 1/(m+1)) = 1/(m+1),也就是1/n。
- 综上可知,算法成立。
将问题一中的条件变为,k为任意整数的情况,即要求最终返回的元素有k个,这就是水塘抽样(Reservoir Sampling)问题。要求是:取到第n个元素时,前n个元素被留下的几率相等,即k/n。
算法同上面思路类似,将1/n换乘k/n即可。在取第n个数据的时候,我们生成一个0到1的随机数p,如果p小于k/n,替换池中任意一个为第n个数。大于k/n,继续保留前面的数。直到数据流结束,返回此k个数。但是为了保证计算机计算分数额准确性,一般是生成一个0到n的随机数,跟k相比,道理是一样的。当生成的随机数小于k的时候,放入池中,否则不放入。
同样采用归纳法来分析:
- 初始情况 n <= k:此时每个元素留下的概率均为1。
- 当 n = k+1 时,第k+1个元素留下的概率为k/(k+1),前k个元素留下的概率均为:k/k * (1 - k/(k+1) * 1/k) = k/(k+1),即上一步留下的概率乘以这一步留下的概率。
- 假设 n = m 时,每个元素留下的概率均为 k/n = k/m。
- 那么,当 n = m+1 时,第m+1个元素留下的概率为1/(m+1),前m个元素留下的概率均为:k/m * (1 - k/(m+1) * 1/k) = k/(m+1),其中:k/m为上一步留下来的概率,k/(m+1) * 1/k 为这一步不能留下来的概率(第m+1个留下来,同时池中一个元素被踢出的概率)。
- 综上可知,算法成立。
给出代码实现
1 | package com.SamplingUtil; |
全排列问题
阿里笔试题:字符串“alibaba”有___个不同的排列。
很简单的排列组合问题,答案是$C_7^3 * C_4^2 * A_2^2 = 420$。可以看成占7个位置的问题,首先ali三个字母可以任意占用7个位置中的三个位置,并且不需要考虑顺序,因为他们在字符串中不存在重复。其次,ba这两个字母是重复的,首先拿出一个a和一个b进行位置的占用,就是4选2的问题,不考虑重复。最后,还剩两个位置两个字母,但是已经有重复的字符存在,所以考虑顺序。如果要输出所有排列顺序,就是一个经典的递归问题。
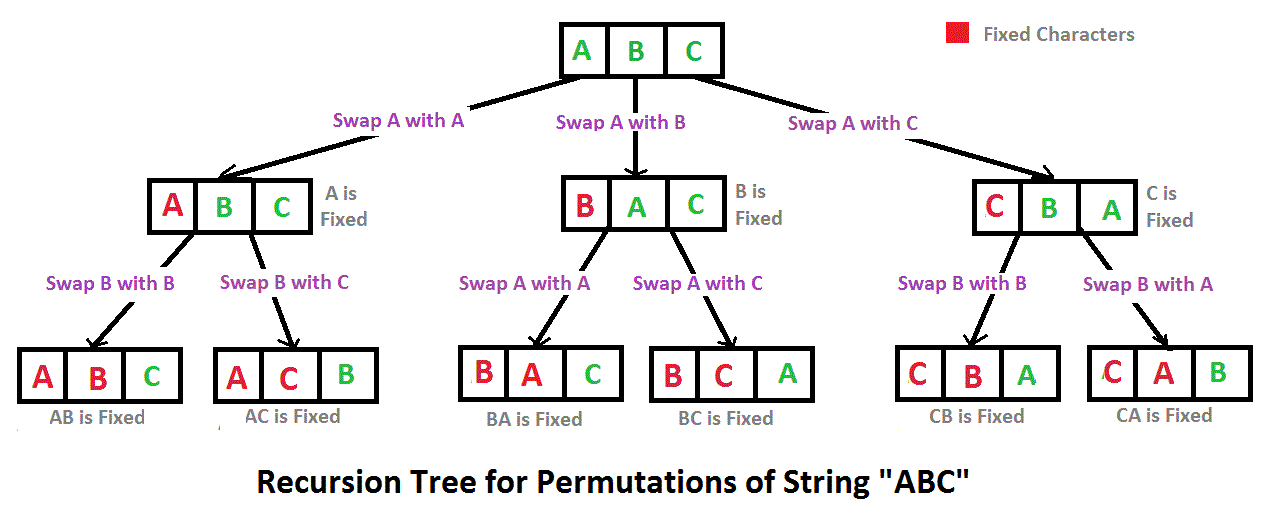
借这个图来理解一下,字符串排序可以认为是固定前n个字符,第n+1个位置的字符和后面位置的字符进行交换,直到字符串长度-1数量的字符被固定就结束递归。
所以问题的解法是这样子的
1 | import java.util.ArrayList; |
LeetCode 46 全排列问题
1 | public List<List<Integer>> permute(int[] nums) { |
Kth问题与topK问题
在刷排序题目的时候,很容易碰到这两个问题,一个是求某个序列中第k个大的数字是什么,另一个就是求一个序列中topK个数字有哪些?这边稍微总结记录一下。
Kth问题,可以参看Leetcode的215题,两个思路,一个是用堆来做,另一个是快排的思路。
先说说用堆的实现,我一开始的想法是既然是要求第K个大,那我用一个大顶堆,把所有的元素都add进去,然后依次poll出来,第k个不就是Kth了嘛,但是显然这样做的空间复杂度是nlogn,如果数量少一些还好,但如果是海量数据呢,还没将所有数据都add进大顶堆中时可能就崩了,其实是要维护一个容量大小为k的小顶堆,当堆的容量不足k个的时候,一直往里面add即可,但是当堆的容量达到k个后,则需要判断入堆的数和当前堆顶的数大小,如果大于当前堆顶的数,则堆顶poll,该数入堆,最后这k个数就是topK大数,此时poll一个数便是第k大的数。同样的,若要求Kth小数,就维护一个大顶堆即可,切记不可搞反。这种用堆的方法还有一个优势就是可以即时运算,求任何时候的第Kth个数。这样的空间复杂度是nlogk。
再说说用快排的思路,实际上是一个快速选择排序的方法,这种方法没有额外的内存消耗,并且时间复杂度也是O(n)级别的,为什么呢,可以这么解释:一般的快排的时间复杂度是nlogn,但是我们只要求找到第k个大小的数字,也就是枢纽等于第k个,并不需要对前后两端进行归并,而只需要找到第k个枢纽的数是什么即可,第一次循环是1,第二次循环复杂度是1/2,第三次是1/4,依次类推,所以最后的和是1+1/2+1/4+1/8+…. < 2,所以最后的时间复杂度是O(2n)也就是O(n)。
topK问题,可以参看Leetcode的347题,也有两个思路,一个是用堆这个和Kth的类似,最后k个的堆中就是所有的topK元素,另一个思路是桶排序,但是我感觉这个和堆排差别也不大。