前言
在之前通过源码角度分析了Dubbo集群容错的服务目录 Directory、服务路由 Router两个部分,本篇主要介绍一下集群Cluster部分,简单介绍Cluster到底是干什么的,简单介绍一下Dubbo的9种集群容错的实现,官方文档上虽然只介绍了主要的5种集群容错模式。
Cluster
1、简介
cluster到底在什么时候用到?以下一段话截取自官方文档
集群工作过程可分为两个阶段。第一个阶段是在服务消费者初始化期间,集群 Cluster 实现类为服务消费者创建 Cluster Invoker 实例,即上图中的 merge 操作。
Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,用不同的容错机制进行处理。
从Cluster类图上就可以看出,有以下这9种,这九个子类中基本的逻辑都是实现主类Cluster的join方法。
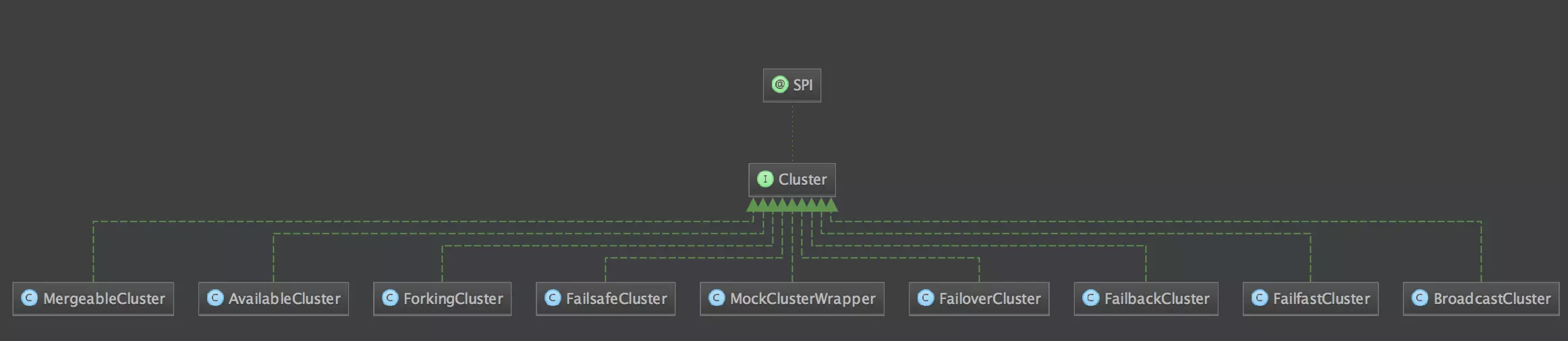
Cluster.java
1 | (FailoverCluster.NAME) |
2、简单介绍九种容错机制
- Failover Cluster - 失败自动切换。Dubbo默认容错机制,会做负载均衡,自动切换其它服务器重试3次(默认次数)。使用场景:读或幂等写操作,重试会加大对下游服务提供者的压力。
- Failfast Cluster - 快速失败。请求失败后返回异常,不进行重试,会做负载均衡。使用场景:非幂等性操作。
- Failsafe Cluster - 失败安全。请求失败后忽略异常,不进行重试,会做负载均衡。使用场景:不关心调用是否成功,eg:日志记录。
- Failback Cluster - 失败自动恢复。失败后记录到队列中,通过定时器重试,会做负载均衡。使用场景:异步或最终一致性的请求。
- Forking Cluster - 并行调用多个服务提供者,只要有一个成功就返回。使用场景:对实时性要求高的请求。
- Broadcast Cluster - 广播多个服务,只要有一个失败就失败,不需要做负载均衡。使用场景:通常用于用户状态更新后广播。
- Available Cluster - 最简单的方式,不会做负载均衡,遍历所有的服务列表,找到每一个可用的服务就直接调用。如果没有可用的节点,则直接抛出异常。
- Mock Cluster - 广播调用所有可用的服务,任意一个节点报错则报错。
- Mergeable Cluster - 将多个节点请求得到的结果进行合并。
3、分析
下面就对这九种集群容错机制进行分析
FailoverCluster
我们进到FailoverCluster类中可以看到,这边重写了join方法,调用到的是FailoverClusterInvoker类,进到这个Invoker中来看一下。
1 |
|
FailoverClusterInvoker.java,这个类中最重要一个函数就是doInvoke,分析一下。
1 |
|
FailfastCluste
上一个FailoverCluster是适用于写操作或者幂等操作,这边的FailfastCluster多是用于非幂等的操作。解释一下,我的理解是如果用FailoverCluster进行写操作这种非幂等操作的时候,如果发生错误,就会进行重试,这样子就会造成写入多条数据,所以写操作多要用FailfastCluster来进行集群的容错机制。这也是“读接口”和“写接口”的区别。
它对应Invoker中的doInvoke函数就简单的多
1 |
|
FailsafeCluster
失败安全,出现异常的时候直接忽略即可,常用于日志的操作。
1 |
|
FailbackCluster
失败自动恢复。失败后记录到队列中,通过定时器重试,会做负载均衡。使用场景:异步或最终一致性的请求。
1 |
|
注意,这边catch中有一个addFailed(invocation, this)函数,这边进来看一下。
1 | private void addFailed(Invocation invocation, AbstractClusterInvoker<?> router) { |
这边用到了scheduledExecutorService线程池,这个线程池在之前介绍任务调度的博客中已经介绍过了,可以看这篇博客。
1 | void retryFailed() { |
ForkingCluster
官网中是这么写的
ForkingClusterInvoker 会在运行时通过线程池创建多个线程,并发调用多个服务提供者。只要有一个服务提供者成功返回了结果,doInvoke 方法就会立即结束运行。ForkingClusterInvoker 的应用场景是在一些对实时性要求比较高读操作(注意是读操作,并行写操作可能不安全)下使用,但这将会耗费更多的资源。
这边实现的代码很长,具体的分析可以参考官网。源码中我整理几个重要的点:1.这边ForkingClusterInvoker中也是要用到线程池的,由于是需要并发调用的,所以就需要为每个 Invoker 创建一个执行线程,将他们用线程池管理起来。2.源码中还在doInvoker 方法中用到了阻塞队列,在发生错误时候,在value >= selected.size()的情况下,才将异常对象添加到阻塞队列中。目的就是可以保证异常对象不会出现在正常结果的前面,这样可从阻塞队列中优先取出正常的结果。
BroadcastCluster
顾名思义,对所有服务的提供者进行用户状态的广播,如果其中一台报错,在循环调用结束后,BroadcastClusterInvoker 会抛出异常。该类通常用于通知所有提供者更新缓存或日志等本地资源信息。
1 | public Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { |
很简单,代码中只需要对每个Invokers逐个进行调用,有异常就捕获,不影响剩下的调用,直到所有调用完毕,返回。
AvailableCluster
最简单的方式,不会做负载均衡,遍历所有的服务列表,找到每一个可用的服务就直接调用。如果没有可用的节点,则直接抛出异常。
1 | public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException { |
源码很简单,只要有一个invoker可用,就返回,否则就抛出异常。也就是满足一个就好。
MockCluster
以下说明来自于官网
本地伪装通常用于服务降级,比如某验权服务,当服务提供方全部挂掉后,客户端不抛出异常,而是通过 Mock 数据返回授权失败
MergeableCluster
以下说明来自于官网
按组合并返回结果 ,比如菜单服务,接口一样,但有多种实现,用group区分,现在消费方需从每种group中调用一次返回结果,合并结果返回,这样就可以实现聚合菜单项。