前言
前三篇博客已经总结完了集群容错的比较重要的三个部分,本篇是集群容错的最后一个部分,也就是负载均衡LoadBalance。负载均衡在任何分布式的项目中都或多或少的会遇见,解决的方法也大同小异,并且,dubbo中的负载均衡在面试中似乎也是一个经常被问到的点。本篇简单总结Dubbo中的集群容错部分。
LoadBalance
1、简介
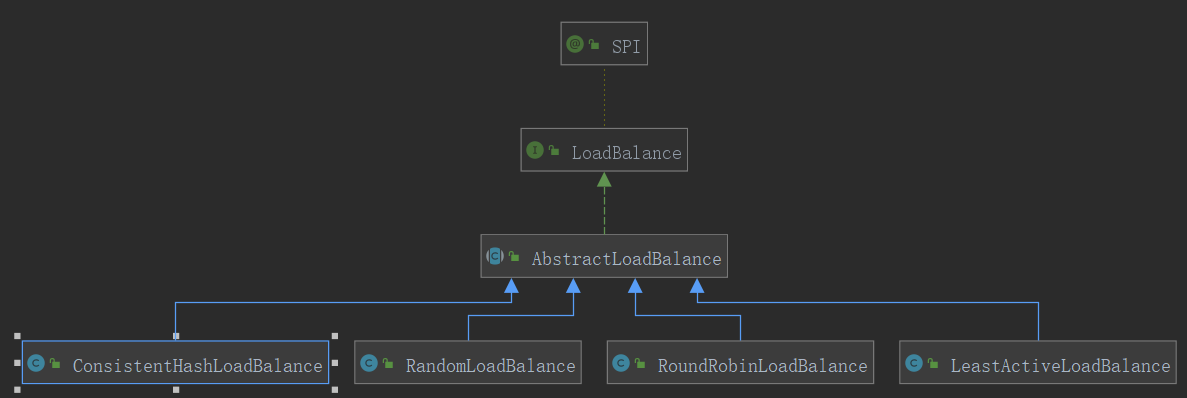
Dubbo提供了四种负载均衡机制,分别是基于权重随机算法的 RandomLoadBalance、基于最少活跃调用数算法的 LeastActiveLoadBalance、基于 hash 一致性的 ConsistentHashLoadBalance,以及基于加权轮询算法的 RoundRobinLoadBalance。
这边也给出相关的类继承关系图。
2、源码分析
AbstractLoadBalance
首先看这个抽象类,当invokers的数量只有一个的时候,不需要负载均衡来选择服务器,而是直接调用即可。当invokers的数量大于1的时候才会调用负载均衡的方法来选择服务提供者。
这里还有一个给服务提供者的降权操作。当服务的运行时常小于服务的预热时常的时候,会给对应的服务进行降权。这里的目的是为了避免让服务启动之初就处于一个高负载的状态,而是让服务启动后“低功率”运行一段时间,使其效率慢慢提升至最佳状态。
1 | (uptime / warmup) * weight |
上面这个公式的意思是一开始服务的启动时间还没有超过服务的预热时间,所以(uptime / warmup)比值是小于1的,所以权重是降低的,当运行时间逐渐增大,也就是uptime和warmup逐渐持平,权重就恢复到原来的权重。
RandomLoadBalance
这个负载均衡策略是加权随机,这个负载均衡策略也是dubbo默认的缺省实现类。这边实现加权随机的方法感觉比较新奇,比如有三个服务提供者,它们分别叫A、B、C,它们的权重为5, 2, 3。那么,为了实现加权随机,Dubbo中采用的策略是先随机生成一个[0, totalWeight)区间的数字,也就是[0, 10),接着用这个随机数字随机减去一个服务的权重,比如随机生成了7,随机减去5先,等于2,大于0,继续减,再随机减去3,等于-1,小于0,所以会落在5到8的区间中。
他这边实现加权随机的做法还是比较有意思的,其实也可以采用统计学里常用的拒绝or接受的判断方式来进行判断,实现的话需要嵌套两个while循环能搞定,只要随机生成一个[0, totalWeight)的数字,然后依次循环去判断选择拒绝还是接受当前的服务器。
LeastActiveLoadBalance
LeastActiveLoadBalance 翻译过来是最小活跃数负载均衡。思路就是为每个服务提供者都赋一个活跃数,初始的活跃数都为0,当一个服务被调用的时候,活跃数加1,当服务调用结束后,活跃数减1,所以最终那些效率高的服务器的活跃数是最小的,故我们可以为它们分配更高的访问概率。实际上,它还加入了权重的概念,比如两个服务提供者的最小活跃数是相同的,但是它们分得的权重不同,这时候权重大的调用的概率高,权重小的调用的概率低。
1 |
|
整个过程的代码思路比较简单,这边稍微总结一下:
首先,遍历整个invoker列表。找到最小活跃数的服务器。
接着,如果有多个invoker有相同的最小活跃数,这时候就需要判断它们的权重是否相同。这里分两种情况讨论,如果权重相同,即随机返回一个即可。如果权重不同,即需要通过权重处理方式来选择一个服务提供者,选择的方法和前面的RandomLoadBalance是一样的,这边就不赘述了。
如果只有一个最小活跃数的invoker,就选择这个作为服务的提供者。
ConsistentHashLoadBalance
一致性哈希算法。可以参考 一致性哈希。dubbo这边将原来的缓存结点换成了服务提供者,其他宕机处理和虚拟节点的方式和原来的一致性哈希算法基本类似。来稍微看一下源码的实现。
一致性 hash 选择器 ConsistentHashSelector 的初始化
1 | private static final class ConsistentHashSelector<T> { |
所以有了以上基于TreeMap存储的哈希选择器,做select的时候只要根据这个TreeMap进行映射即可。
1 |
|
继续来看一下select方法,这几个方法是在内置类ConsistentHashSelector中的方法。
1 | public Invoker<T> select(Invocation invocation) { |
如上,选择的过程相对比较简单了。首先是对参数进行 md5 以及 hash 运算,得到一个 hash 值。然后再拿这个值到 TreeMap 中查找目标 Invoker 即可。
RoundRobinLoadBalance
加权轮询负载均衡。首先来解释一下,轮询的意思就是几台服务器轮着来访问,比如说我有A、B、C三台服务器,第一次访问服务器A,第二次访问服务器B,第三次访问服务器C,下一次又接着访问服务器A,以此类推。那么加权轮询的意思就是,比如我给出了三个权重,5、2、3,分别对应着A、B、C三台服务器,当轮询的访问次数分别是3、2、2的时候,下一次按道理应该是访问B了,但是由于B的权重只有2,所以下一次可能分配到的就是C,而不是B。最终,让所有服务提供者的访问概率在5:2:3。
我参看了官方的文档,发现RoundRobinLoadBalance这个负载均衡策略似乎被重构了好几个版本。这边就拿最后的版本来解析。最后一个版本的重构是基于Nginx的平滑加权轮询负载均衡。下面以官方的例子来解释一下。
| 请求编号 | currentWeight 数组 | 选择结果 | 减去权重总和后的 currentWeight 数组 |
|---|---|---|---|
| 1 | [5, 1, 1] | A | [-2, 1, 1] |
| 2 | [3, 2, 2] | A | [-4, 2, 2] |
| 3 | [1, 3, 3] | B | [1, -4, 3] |
| 4 | [6, -3, 4] | A | [-1, -3, 4] |
| 5 | [4, -2, 5] | C | [4, -2, -2] |
| 6 | [9, -1, -1] | A | [2, -1, -1] |
| 7 | [7, 0, 0] | A | [0, 0, 0] |
这里A、B、C三个服务提供者的权重分别是5、1、1。分为weight 和 currentWeight,其中weight是固定不变的,也就是5、1、1。而currentWeight是会动态变化的。
这样子选择出来的结果就是[A、A、B、A、C、A、A],就不会有之前的让所有A都在一块的情况。
3、总结
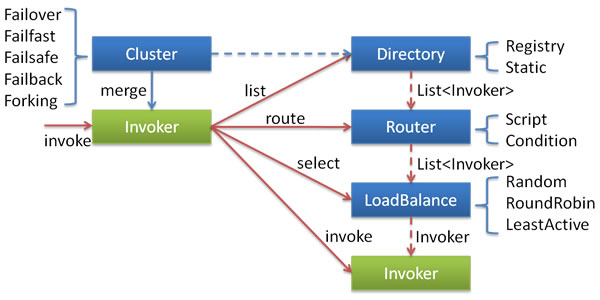
学习完集群容错的四大块内容,总结起来就是官方的这张图,后面会再结合一个具体的例子debug进去分析一波。