前言
RocketMQ分布式集群是通过其中各个模块的配合实现高可用,RocketMQ的高可用主要可以从Producer、Consumer、Broker和NameServer出发来分析,本章旨在通过源码来简单分析其中Producer的高可用原理。其他部分在后续章节继续分析。
一、消息发送的流程
消息发送主要的步骤为:验证消息、查找路由、消息发送(包括异常处理机制)
消息验证:消息长度验证
在发送消息之前,首先需要确保生产者处于运行状态,然后验证消息是否符合相应的规范,具体的规范要求是主题名称、消息体不能为空、消息长度不能等于0且默认不能超过允许发送消息的最大长度4M(maxMessageSize=1024*1024*4)
查找路由
消息发送
- 检查消息发送是否合理
- 检查该broker是否有写权限
- 检查该Topic是否可以进行消息发送
- 在nameserver端存储主题的配置信息
- 检查队列,如果队列不合法,返回错误码
- 如果消息重试次数超过允许的最大重试次数,消息将进入到DLD延迟队列。延迟队列主题:%DLQ%+消费组名。
- 调用DefaultMessageStore#putMessage进行消息存储。
注意:消息发送方式有三种,分别是同步发送、异步发送和单向发送。其中同步和异步都可以控制重试次数,但是单向没有重试机制。
二、Producer发送消息高可用
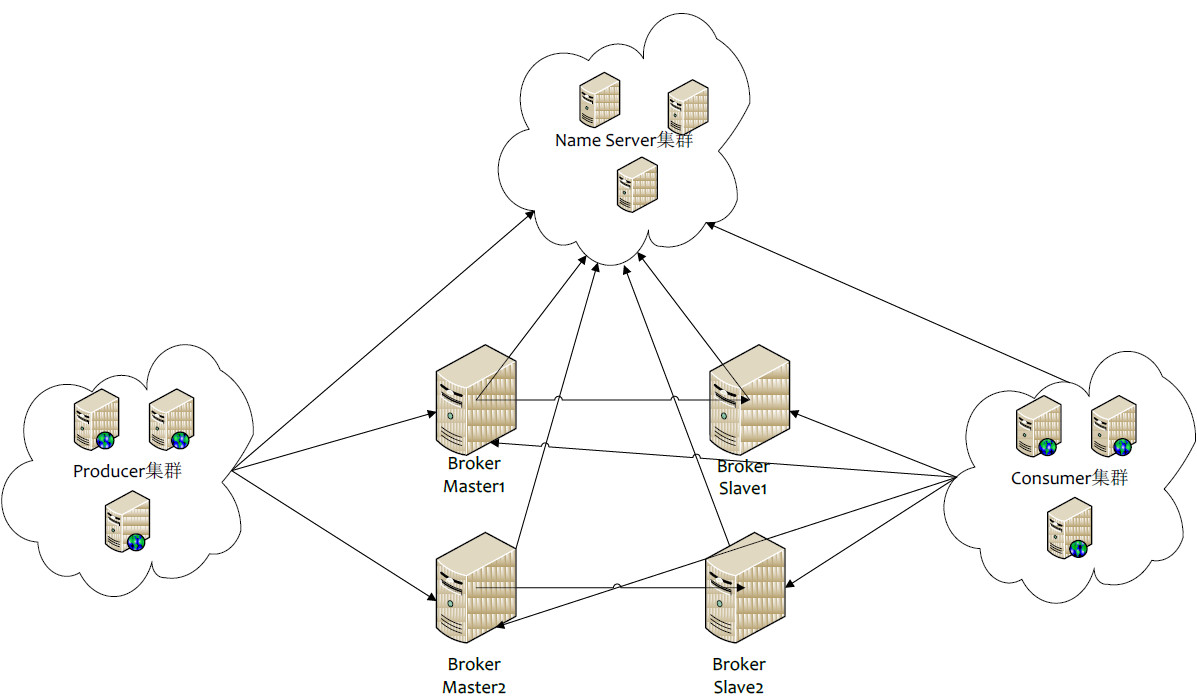
在消息创建消息时,需要为每一个消息指定一个topic。topic会创建在每一个Broker组中,也就是说即使一个Broker组的Master不可用了,但是集群中其他Broker组仍然可以接收生产者生产的消息,Producer仍然可以发送消息。下面通过定位到发送消息的源代码看其如何实现高可用。
首先要发送一条消息通常代码逻辑是这样子的,在基础概念的篇章就详细的介绍了关于各种类型消息的生产和发送的方法,可以回顾这篇博客。
1 | public static void main(String[] args) throws Exception { |
让我们跟到send方法里面进去看一下,进到org.apache.rocketmq.client.producer.DefaultMQProducer类中
1 |
|
继续跟进去,到这步分析一下,进到org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl类中,因为消息发送有三种模式,分别是同步发送消息,异步发送消息和单向发送消息,最终都是调用的该类下的sendDefaultImpl方法,通过参数来选择消息的发送方式。
1 | public enum CommunicationMode { |
sendDefaultImpl通过communicationMode参数来选择三种消息发送方式中的一种,sendCallback参数来设置是否有回调,这边同步和单向都是没有回调方法的,只有异步才有回调,从而来对消息发送结果返回做出进一步处理。以下是总的代码,很长一段,后面会有相应断点的解释。
1 | private SendResult sendDefaultImpl( |
代码很长,分开解释一下,首先进入到断点1中tryToFindTopicPublishInfo
1 | private TopicPublishInfo tryToFindTopicPublishInfo(final String topic) { |
断点2:producer发送消息的负载均衡策略。
1 | public MessageQueue selectOneMessageQueue(final TopicPublishInfo tpInfo, final String lastBrokerName) { |
先来简单介绍不开启Broker故障延迟机制的情况,也就是上面②的情况,默认情况下是不开启的。见如下的代码。
1 | public MessageQueue selectOneMessageQueue(String lastBrokerName) { |
总结不开启故障延迟机制的情况,这边我一开始是有一个疑问的。既然已经有了这种失败不选择的机制,为何还要有后面的故障延迟机制呢?答案是上面的这种普通的故障处理方法只能规避上一次失败的broker,而不能规避两个及以上的broker的情况,比如上次失败的broker记录的是A机器,但是在轮询到B机器的时候,B也发生了故障,但是lastBrokerName却记录的是上一次失败的broker,也就是A,那么B这台宕机的机器还是被选择到了,没有被有效的规避掉,消息仍然不能成功发送。以上就是这种机制的问题所在,所以才有了下面的故障延迟机制的出现。
结合RocketMQ的书和源码又理解了一下:这边选择的话不管是否开启故障延迟机制都是通过轮询的方式进行负载均衡的选择,只不过一开始的选的MessageQueue是随机数选出来的,后面的是通过加1的操作一个一个轮询过去。一般默认情况下,一个topic的消息对应了一台broker中的四个MessageQueue,比如
Broker-A中有四个MessageQueue,分别是A-queue-id=0、A-queue-id=1、A-queue-id=2、A-queue-id=3
Broker-B中有四个MessageQueue,分别是B-queue-id=0、B-queue-id=1、B-queue-id=2、B-queue-id=3
在不开启故障延迟机制的情况下(一般默认也是不开启这个机制的),假如一开始通过随机数出数字3,那也就会选择到A-queue-id=2这个MessageQueue,如果发送消息失败,这时候就会记录下这个MessageQueue的brokerName到一个LastBrokerName变量中,继续发送消息,那么这次消息的发送就不会发送到LastBrokerName中记录的那个broker中的A-queue-id=3,而是发送给B-queue-id=0,所以不开启集群容错在发送本消息的时候能规避掉上次失败的那个broker。但是会有两个问题
- 第一个问题是其他消息发送的时候也可能会选择到这台故障的broker,还是会引发重试,带来不必要的性能损耗(解释一下为什么故障了的broker仍然可能被其他消息选择到呢?首先,NameServer检测Broker是否可用是有延迟的,之前有提到是10s做一次心跳检测,其次NameServer不会检测到Broker宕机后就马上推送消息给消息生产者,而消息生产者是每隔30s更新一次路由信息,所以并不能马上感知到这个Broker是故障的)。
- 第二个问题是它只能记录下上次失败的那个broker的信息,而可能上上次失败的broker不会被记录下来,上上次的broker可能还是处于宕机状态,这点也就是之前理解到的,可以看一下上面的解释。
所以引入了故障延迟机制。
当开启故障延迟机制的时候,见原来代码中的注释。
ok,回到原来断点2的位置,接下去的逻辑就是用sendKernelImpl方法进行消息的发送,并用updateFaultItem进行broker可用性的更新。updateFaultItem进行broker更新一般发送消息来说只需要更新一次,因为消息发送成功了就不用再尝试发送了,但是当消息发送失败的时候会在不同的catch中也会进行broker的更新操作。
1 | private long[] latencyMax = {50L, 100L, 550L, 1000L, 2000L, 3000L, 15000L}; |
最终这个规避时间是体现在上面开启Broker故障延迟机制的selectOneMessageQueue函数相应的逻辑中,给所有发送消息失败的broker都设置延迟,只有当到了延迟的时间,最终才会有效,且能有机会被重新选择到。
总结:
在分析Producer过程中遇到的坑就是文章中提到的不明白为何在有了一个负载均衡机制的情况下还要有一个故障延迟机制,在仔细研究相关部分的代码后问题算是很好的解决了。
我认为Producer的高可用主要体现在以下几个方面。首先,在消息创建消息时,需要为每一个消息指定一个topic。topic会创建在每一个Broker组中,也就是说即使一个Broker组的Master不可用了,但是集群中其他Broker组仍然可以接收生产者生产的消息,Producer仍然可以发送消息。其次,光能选择其他broker也是不行的,还需要有容错的机制,也就是上面提到的默认的记录上一次失败broker的机制以及后面分析的故障延迟机制,都能让无法正常工作的broker被频繁连接,以免造成发送数据的成功率低和加快效率低的问题。
参考