前言
锁的出现防止了在多线程的情况下对一些共享变量的错误操作,一般用的最多的锁无非是synchronized和Lock,在单机的情况下能保证线程的安全性,但是在分布式的情况下这种加锁方式并不能保证线程的安全性,因此提出分布式锁的概念。分布式锁的实现主要有Redis、Zookeeper、Mysql等,本篇主要介绍基于Redis和Zookeeper的分布式锁实现。
基于Redis的分布式锁
分布式锁的想法
要实现基于Redis的分布式锁,一个非常重要的Redis方法就是setnx,这个方法的作用就是SET IF NOT EXIST,也就是当key的值不存在的时候,就进行set操作,当key存在则不操作。但是光设置了值远远是不够的,万一当在设置完值之后某台服务器的Redis就宕机了,这个锁岂不是永远都释放不了了嘛,所以这边还应该设置一个过期时间,即使在宕机之后也能释放掉锁。设置过期时间用到的就是expire操作。
那么是否把setnx命令和expire一起用就可以了呢,其实也是不行的,依然会存在锁释放不了的情况,因为setnx和expire两句话的执行并不是原子性的操作,在setnx之后宕机了依然还没有设置过期时间,不就和之前的那种情况一样了么。所以Redis还为我们提供了一个set的操作,它可以看作是setnx和expire的合并操作,且能保证原子性。
1 | SET key value NX PX 1000 |
key就是键,这边设置为同一个key值就行,value就是属于每一个加锁的请求的一个id值,每次都要确保不一样,在解锁的时候就是靠这个id值来判断是否是当前请求加的锁。所以value可以用UUID或者雪花算法来确保生成的每个值都不一致。
代码实现
1 | public class sellGoods extends Thread{ |
上面是模仿15个用户来争抢10个商品的情况,为了不超卖,一般都会加锁来实现,加Synchronized或者Lock其实都能实现,比如上面的这种直接加Synchronized的情况。而在实际情况中,系统是部署在多个机器中的,会出现多个进程并发问题,单纯的加线程的锁是无法解决问题的,为了方便就暂且用这种情况来模拟一下分布式锁的实现。
加锁的函数
1 | /** |
简单再解释一下这边的jedis.set()
lock_key:key来当锁,并且它是唯一的。
requestId:为了保证解锁的请求是加锁的同一个请求,而不是把其他请求加的锁给解了,这边要求每个请求都要有一个requestId来保证加锁解锁是同一个顾客发起的请求。
SET_IF_NOT_EXIST:这个参数我们填的是NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作。
SET_WITH_EXPIRE_TIME:这个参数我们传的是PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。
expireTime:与第四个参数相呼应,代表key的过期时间。
解锁的函数
1 | /** |
在解锁的时候,我们用LUA脚本来完成删除的这一原子操作。先判断当前锁的字符串是否与传入的值相等,是的话就删除Key,解锁成功,返回1。
测试函数
1 | public class sellGoods extends Thread{ |
其实在使用的时候,可以通过redisson这个客户端工具去直接使用。
基于Zookeeper的分布式锁
分布式锁的想法
通过ZK去实现分布式锁主要是因为ZK的结点唯一,也就是说,不能重复的去创建同一个名字的结点,与Redis中的类比,就像是Redis中的Setnx一样,保证了有值的时候不操作,没有值的时候创建结点。在ZK中有四种类型的结点,分别是持久化的结点、持久化顺序结点、临时的结点和临时顺序结点。这边需要考虑用哪种结点来实现我们的分布式锁。
首先一点,要考虑宕机的情况,如果我们采用持久化结点的做法,一旦获取到分布式锁之后机器宕机,那么结点就不能释放锁,所以一般考虑用临时结点来进行存放,避免死锁的问题。其次,如何知道是否可以去竞争锁了呢,难道要采用和redis一样的循环尝试么?其实ZK为我们提供了watch机制,也就是当一个锁已经释放(结点删除),就可以通知其他请求来争抢锁,但是这样也不是最好的,因为容易产生羊群效应,造成系统资源的浪费,因为大家都去争抢锁了,其实也就只有一个请求能成功获得锁。所以最好的做法是采用顺序的结点,当watch到前一个锁释放了,那么当前请求就获得锁,是按照一个顺序的方式去进行锁的分配。综上,结点的类型应该采用临时顺序结点。
来梳理一下整个实现流程:
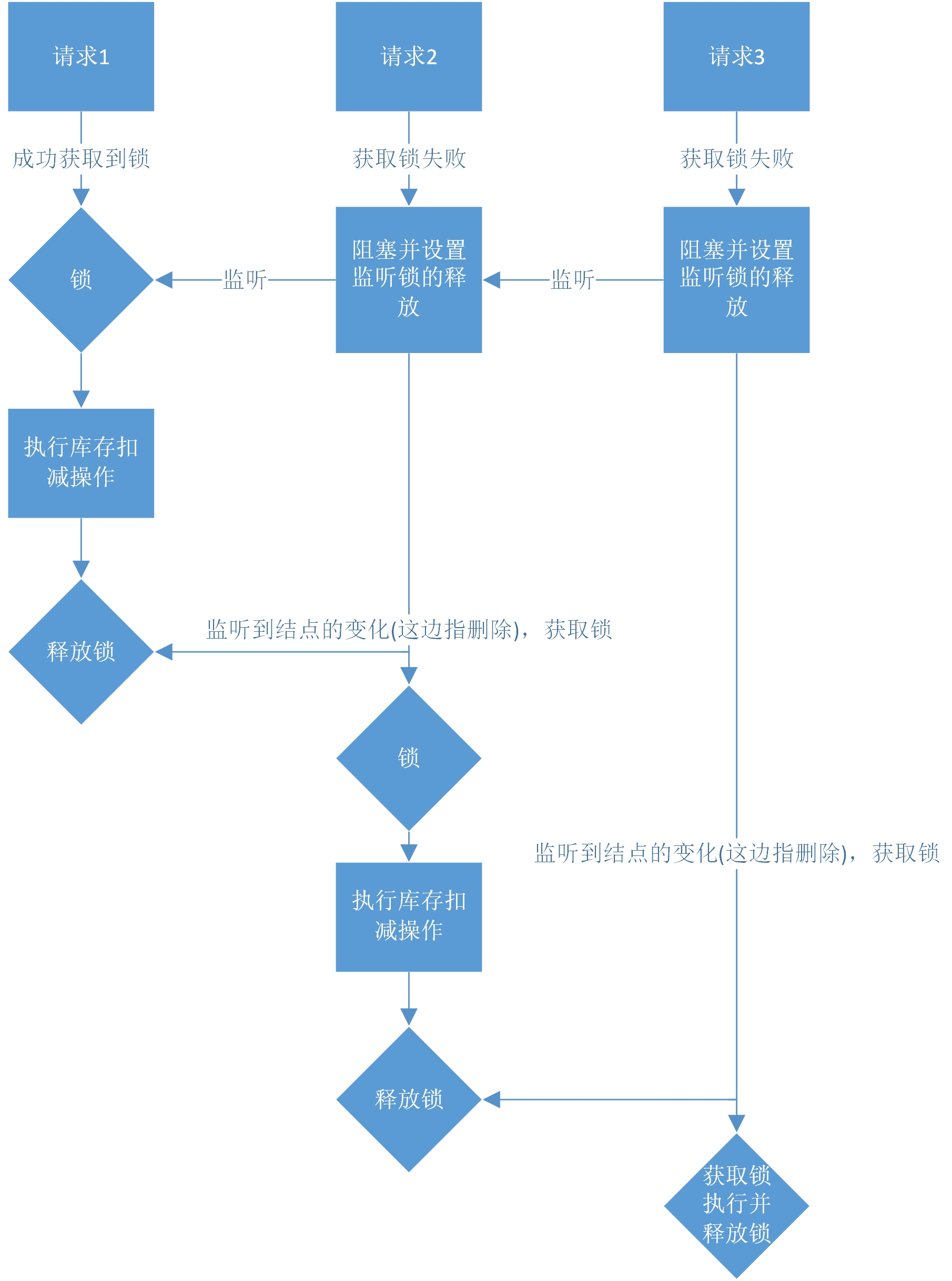
代码实现
加锁与解锁
1 | public class myZKLock implements Lock { |
测试函数与Redis中的类似。
对比
性能上来说,Redis是NoSQL数据库,相对比来说Redis比Zookeeper性能要好。
可靠性来说,Redis有效期不是很好控制,容易产生Redis分布式锁过期时间到了,但是业务代码还没有执行完的情况,这样的话就需要续期(续期一般可以启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端还持有锁key,那么就会不断的延长锁key的生存时间)来操作,而Zookeeper可靠性比Redis更好,由于是临时结点,所以一旦宕机结点就会自动释放,不存在设置有效期的这种情况。